
REID-CBD is a new multi-site dataset collected in a city CBD, in which most images were captured in nonadjacent scenes, so that the identities rarely appeared across camera views. This real-world scenario is still largely ignored. REID-CBD is collected to facilitate research on semi-supervised re-identification on identities rarely crossing camera views.
Please send a signed dataset release agreement copy to wuanc@mail.sysu.edu.cn.
If your application is passed, we will send the download link of the dataset.
Every pedestrian captured in "train_labeled" folder of REID-CBD has signed a privacy license to allow the images to be used for scientific research and shown in research papers.
The other pedestrians are not allowed to be shown publicly, whose faces are masked to avoid privacy problem.
Testing code: https://github.com/wuancong/REID-CBD/tree/main/evaluation
If you use the dataset, please cite the following paper:
Ancong Wu, Wenhang Ge, Wei-Shi Zheng. Rewarded Semi-Supervised Re-Identification on Identities Rarely Crossing Camera Views. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023 (DOI: 10.1109/TPAMI.2023.3292936).
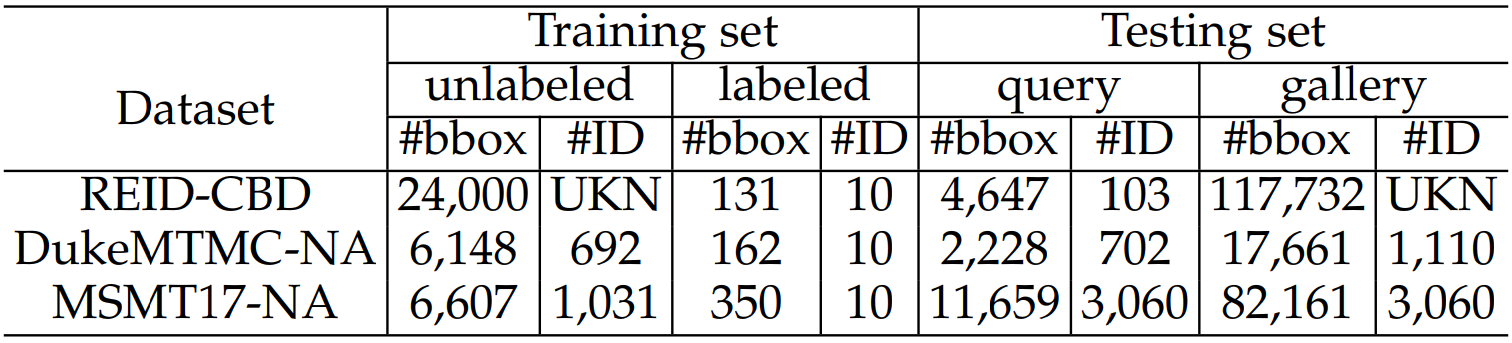
REID-CBD contains 146,510 pedestrian images captured from 6 cameras of 6 sites. The dataset consists of unlabeled training set, labeled training set and testing set. For constructing unlabeled training set, 4000 person images were sampled from bounding boxes detected from videos of each camera. For constructing labeled training set and testing set, we arranged for 113 actors to appear in all 6 scenes and then captured and annotated their images. Images of 10 actors were used as labeled training set and images of other 103 actors were used as testing set. In testing set, the images of 103 actors are split half-and-half for each identity to form the query image set and the gallery image set. The 113,031 images as distractors are added to the gallery set.
Here are some examples and statistics of REID-CBD:
In "REID-CBD.zip", the files of training set and testing set are listed in txt files as follows:
In our paper, we construct simulated datasets from existing benchmark datasets MSMT17 and DukeMTMC. The lists of training data are in https://github.com/wuancong/REID-CBD/tree/main/simulated_datasets. The testing sets and evaluation protocols are the same as the original datasets.
If you have any questions, please feel free to contact wuanc@mail.sysu.edu.cn.
Author homepage: isee-ai.cn/~wuancong.